Transit NXT – Capture new markets faster
グローバリゼーションの進展により、企業が新製品を市場に投入する際には、その製品情報を様々な言語で迅速に展開することがますます重要になっています。 その一方で、情報の種類は、取扱説明書、ウェブサイト、ユーザーインターフェースなど多岐に渡り、それらをすべて翻訳するには、膨大な労力が必要となり、そのデータ管理も大きな負担になります。
シュタールが翻訳会社として蓄積してきた経験とノウハウを活用して開発した翻訳メモリシステム Transit NXT なら、このような問題を一挙に解決できます。一度、Transitで翻訳すれば、過去の翻訳を簡単に再利用できるため、次のバージョンアップでは、本当に新しく追加されたテキストの翻訳のみに集中でき、翻訳の品質と一貫性を向上させながら、同時に貴重な時間と翻訳コストを削減できます。
Transit NXT は迅速な投資収益を確保するために、過去の翻訳資産を最大限に活用します。
How?
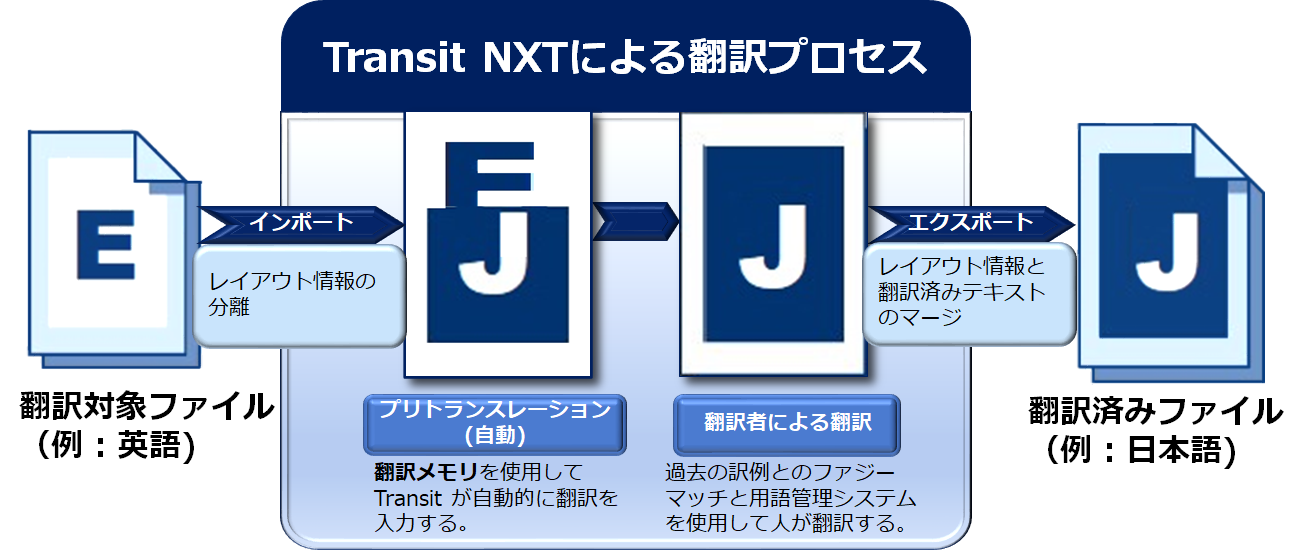
Transit ではまず翻訳対象ファイルを取り込み(インポート)、高性能なフィルタを使用して、ドキュメントから翻訳対象テキストを抽出します。テキストを抽出したら、過去の翻訳(翻訳メモリ)を自動的に検索し、それらのテキストが過去に翻訳されたことがあるかどうかをチェックし、もし翻訳されたことがあれば、その翻訳はすべてTransit 内で自動的に訳文にコピー&ペーストされます(プリトランスレーション)。
プリトランスレーションの後、翻訳者が残りの未翻訳箇所を翻訳する際にも、翻訳メモリ内に過去に翻訳した文章に似ているテキストがないかどうかが一文ずつ自動的にチェックされ、見つかれば、類似する翻訳例(ファジーマッチ)として提示されます。これにより、翻訳作業の労力が軽減され、訳文の品質も向上します。またその製品特有の用語辞書があれば、それらの用語も、Transit 上でわかりやすく表示され、翻訳者は簡単な操作でその訳語を取り込むことができます (TermStar)。
このようにTransitは、翻訳メモリと用語辞書を使用して新しいプロジェクトを効率的に完成させます。翻訳メモリは、プロジェクトが完了する度に、ますます充実してゆきます。
Benefits for you
- 翻訳とローカライズにかかる時間と費用を削減。
- 既存の翻訳メモリの最適な使用を重ねていくことにより、迅速な投資回収が可能。
- 詳細なレポート機能が、費用・スケジュール管理に有効。
- 汎用性の高い翻訳メモリ(マルチフォーマット、多言語、多方向)。
- 特定のレビューモード、多数のチェック機能、詳細な品質レポート、セグメント毎の変更履歴のトラッキングによる効率的な品質保証。
- 過去訳のコンテキストが簡単に参照でき、より高品質な翻訳が可能。
- TermStar辞書に登録されている用語の過去の使用例をダイナミックに検索。
- 他の多くのデータベース型の翻訳メモリ製品と異なり、翻訳メモリがテキストベース(XML)で保存されるため、処理速度が速く、共有も容易など、管理の負荷が格段に軽くなります。
Edition
Transit NXTには3つのエディションがあります。
●Transit NXT Professional : 660,000円(本体価格 600,000円)
Transitのすべての機能が使用できる最上位エディション。翻訳プロジェクトの費用・スケジュールを管理し、必要なファイルを準備して複数の翻訳者に送る大きな翻訳プロジェクトの管理者向け(単独で翻訳を行い、完結することも可能)。
● Transit NXT Freelance Pro : 330,000円(本体価格 300,000円)
Word や Excel などのオフィス文書を単独で翻訳する企業内翻訳担当者、またはフリーランス翻訳者向けのコンパクトなエディション(Professionalで準備した翻訳プロジェクトを受け取って翻訳することも可能ですが、Freelance Proで準備したプロジェクトを他のユーザーに送ることはできません)。
● Transit NXT Workstation : 275,000円(本体価格 250,000円)
プロジェクトを作成することはなく、プロジェクトマネージャーから依頼を受けた翻訳作業のみを行う翻訳者向けのエディション (Transit NXT Professionalで準備した翻訳プロジェクトが存在することが前提で、単独でプロジェクトを完結することはできません)。
FAQ~よくあるご質問
購入ご検討のお客様
Transitを導入することで、どのような効果を期待できますか?
例えば製品マニュアルでは、Transitを使った翻訳メモリが蓄積されると、改訂時に翻訳が必要になるのは更新された箇所のみになります。
内容がほぼ同じである製品マニュアルを翻訳する際にも、共通する部分の翻訳は不要となるため、大幅なコストカットと翻訳期間の短縮が期待できます。
また、翻訳後は元のレイアウトが保たれるので、翻訳のコピーペーストを行う必要がなく、翻訳後の工期短縮にもつながります。
お客様の実際のデータでどの位お得になるか、無料で試算致しますので、まずはお問い合わせください。
既存のマニュアルが多数あるので、これらの翻訳を活用したいのですが、可能ですか?
可能です。既存のマニュアルをTransitで読み込み、アライメント作業をすることで、翻訳メモリを作成することができます。
*アライメント作業とは、原文と翻訳のペアを作成し、メモリ化する作業です。
エクセルの用語集があるのですが、Transit上で使用できますか?
はい、できます。TransitにはTermStarという用語集があり、既存の用語集を変換することで引き続き使用することができます。
翻訳中は、用語集に登録されている単語はわかりやすく表示され、簡単に訳文に取り込むことができるので、効率的に翻訳作業を進められます。
以前、他社の翻訳メモリツールを使用していました。Transitは他社の製品とメモリを共有できますか?
すでに他の翻訳メモリツールによって蓄積されたメモリがある場合は、翻訳メモリの互換フォーマットであるTMXに変換することで、Transitでも使うことができるようになります。
類似する他社の翻訳メモリツールに比べて、優れているところはどこですか?
無償アップデートによって様々な機能が追加されるため、頻繁なバージョンアップによる追加費用などは発生せず、初期費用のみで長くお使いいただけます。
また、翻訳メモリもデータベースを使用せず、ファイルごとのXML形式で蓄積していくため、容量も小さく管理も容易になります。
機械翻訳には対応していますか?
はい、一部の有料機械翻訳サービスと組み合わせて使用できます。
(有料機械翻訳サービスはお客様ご自身で契約する必要がございます。)
Transitが対応しているデータ形式は何ですか?PDFは取り込めますか?
Microsoft Officeドキュメント各種、Adobe FrameMaker、Adobe InDesign、Adobe PageMaker、Interleaf/QuickSilver、AutoCAD、HTML、XMLファイルなどに対応しています (一部有料)。
PDFの場合は、DOCX、XMLなど他の形式に保存し直す必要があります。
翻訳の後、校正を行いますが、どのように結果を反映できますか?
本プロジェクトを開いて、直接データを修正できます。
用語の変更が入った場合は、用語検索による抽出/修正も可能です。
サポートにはどのような内容が含まれますか?
主に下記項目となります。
-最新情報のご提供
-サービスパックの無償提供
-問題解決のサポート
-お客様のデータにあわせたカスタマイズ
*ただし、作業内容によっては別途費用を請求させて頂く場合がございます。
インストールするPCの推奨環境を教えてください。
Intel Pentium(または互換プロセッサ) : 2GHz 以上
メモリ : 1GB以上
ハードディスク空き容量 : 1GB 以上
SVG グラフィックスカード : 1280 x 1024 ピクセル以上
Windows 7/8/10
Windows Server 2008 R2/2012/2016
ユーザーのお客様
ユーザーロールとは何ですか?効果的な使い方を教えてください。
翻訳、翻訳のチェック、マークアップ(タグ)の割り当てなどの翻訳プロセスの各サブタスクに合わせて、①ウィンドウの表示と配置、②ランゲージウィンドウ内のマークアップなどの表示設定、③用語と辞書の表示設定、④不要な機能の非アクティブ化、の設定を最適化したプリセットです。
ユーザーロールは、リソースバー | [ユーザーロール] | [標準ユーザーロール] から切り替えられます。
ユーザーロールを任意のものに切り換えると、そのロールタスクに必要な機能のみが使用できるようになります。
すべての機能を使用できるのは「スーパーユーザー」です。
設定を変更し、インポートする内容を変更することはできますか?
一部のフィルタでは、マスターページや、ファイルには表示されない宣言部、隠しテキストなども翻訳の対象(または非対象)にすることができます。
[プロジェクト設定]の[ファイルタイプ]タブにある[オプション]をクリックすることで、フィルタ固有の設定を行うことができます。
プロジェクトを作成する際には毎回、1から設定を作り直す必要がありますか?
いいえ、以前作成した設定と基本的に同じで問題なければ、前回のプロジェクトをベースにして作成することは可能です。
元になるプロジェクトを別名で保存し、言語や作業フォルダ、対象ファイル、参照マテリアルなど、新しい翻訳プロジェクトにあわせてプロジェクト設定を変更してください。
重複が多いマニュアルがあるのですが、効率的な方法はありますか?
重複が多い場合、インポート時に翻訳抽出ファイルを作り、そのファイルで翻訳作業を行うことで、新規翻訳の部分のみに集中して作業できます。
あとから重複部分をランゲージペアにマージさせることで、すべてが翻訳されているランゲージペアが作成されます。
これにより、時間の短縮、手間や費用の削減につながります。
翻訳抽出ファイルの作成:インポート時に[設定]→[抽出]→[翻訳抽出ファイルを作成]にチェックいれる/[重複するセグメントのみを抽出]にチェックを入れない→インポート→ランゲージペアと翻訳抽出ファイルが作成(翻訳は抽出ファイルで進めます)。
戻し方:[プロジェクト]の[抽出ファイルのマージ]を押す→ランゲージペアに翻訳抽出ファイルの翻訳+重複部分が反映。
インポート/エクスポートの時にエラーが出ました。どうすれば良いでしょうか。
インポートの時にエラーが出る場合は、設定したフォルダやファイルのパスが正しいかをご確認ください。
また、インポート対象のファイルが閉じているかをご確認ください。
エクスポートの時にエラーが出る場合は、フォーマットのチェックをして、マークアップに不具合が無いかをご確認ください。また、CODファイルが作業フォルダに正しく入っているかもご確認ください。
フォーマットチェックとは、翻訳内の特定情報(例:スペースの数が正しいか、数字の表記が仕様やターゲット言語の表記規則に従っているかどうか)が妥当かどうかを確認することです。
フォーマットチェックは、[レビュー]|[フォーマットチェック]の[開始]ボタンの矢印をクリックして開始します。
プロジェクトのパック/アンパックはどのようにすればいいですか?
リボンバー | [プロジェクト] | [交換] | [パック] を選択すると、プロジェクトマネージャーは翻訳パッケージ(PPF、Project Package File)を作成して送信できます。
リボンバー | [プロジェクト] | [交換] | [アンパック] を選択すると、PPFをアンパック(受信)できます。
統計情報の見方を教えてください。
3種類のレポート(インポート/進捗/翻訳)はどれも、まずターゲット言語の各セグメントのステータスを解析します。
次にソースまたはターゲットのセグメントのワード数と文字数を算出し、そのセグメントのステータスに応じてそれらの数値を割り当てます。
一般的に最も使用頻度が高いインポートレポートでは、次のステータスが区別されます。
•プリトランスレーション:インポート時にプリトランスレーションされたセグメント
•要確認:プリトランスレーションされたが、確認が必要なセグメント
•xx%–yy%:設定したパーセンテージのファジーマッチのセグメント
•未翻訳:プリトランスレーション、要確認、設定したパーセンテージのファジーマッチのいずれにも該当しないセグメント
•重複(IR):設定した回数に基づく重複のセグメント (設定で、全体通しての数かファイルごとの数かを設定できます。)
エクスポートする際にフォントを変換することはできますか?
はい、「ファイルタイプ」の「フォントマッピング」で、エクスポートするファイルのフォントを置き換えることができます。
マークアップとは何ですか? 翻訳中に削除しても良いですか?
マークアップとは文章内に入っているに囲まれた青字部分です。フォント情報や画像など様々な情報が含まれているので、基本的には削除しないでください。特に一部の重要なマークアップを削除してしまうと、エクスポートエラーとなる原因となります。
マークアップの表示はどこで切り替えますか?
リボンバーの[ビュー]タブ→[テキスト/マークアップ]→[マークアップ]のプルダウンで選択できます。
非表示にすると、テキストが無いマークアップのみのセグメントは隠れますので、翻訳時は見やすくなると思います。
削除されてしまったマークアップの挿入方法を教えてください。
1. マークアップを挿入する箇所にカーソルを置く、またはマークアップで囲みたいテキストを選択します。
2. Ctrlキーを押しながら、挿入したいマークアップIDを押します。
この時、IDの入力はテンキーではない数字キーを使ってください。
3. その後、矢印キーを押すとカーソル位置、または囲んだテキストの前後に、指定したマークアップが挿入されます。
太字や斜体などの書体マークアップは、 [編集] タブ | [書式] グループからも挿入できます。
詳しくは、Transit NXT ユーザー ガイドの「6.5.3 翻訳中のマークアップのコピーと挿入」をご参照ください。
特定の用語が含まれるセグメントのみを表示させるにはどうすればよいですか?
1. 確認したい用語をコピーし、リボンバー |[ビュー] | [セグメントフィルタ]|[作成]を選択します。
2. [セグメントフィルタ]ウィンドウが開くので、[セグメントのコンテンツ]欄に先ほどコピーした用語をペーストします。
3. [フィルタ適用]を押すと、確認したい用語が含まれるセグメントだけが表示されます。
訳語が統一されているかの確認時などに便利です。
セグメント訳語検索はどのような機能ですか?
ソース言語のファジー検索で訳語が見つからなかった場合に、ターゲット言語を対象に訳語を検索する機能です。
複数のファイルの内、一部のランゲージペアだけ開けないという警告が出ました。どうすれば良いでしょうか?
ファイル名やフォルダ名に、ウムラウトやアクセント記号などが含まれていると、正しく情報が書き込まれず、ファイルが開けなくなることがあります。
翻訳元のファイル名をこれらの文字を使わないものに変更し、プロジェクト設定の「ファイル」タブで再指定し、再インポートを行ってください。
英数字前後にある半角スペースをカーソルで確認するのが手間なのですが、何か良い方法はありますか?
リボンバーの[ビュー]タブ→[テキスト/マークアップ]→[特殊文字]をチェックしてください。
半角スペースの個所に規定の記号が表示され、一つ一つカーソルで確認する手間が省けます。
プロジェクトマネージャーが言っている訳例が、こちらでは見えません。どうすれば良いでしょうか?
プロジェクトマネージャーが設定しているファジーマッチのパーセンテージと数値を同じにしてみてください。
セグメントステータスやセグメント情報の見方を教えてください。
任意のセグメントにカーソルを置き、Alt+4(テンキーではない数字キー)でセグメント情報ウィンドウが表示されます。
リボンバー[ウィンドウ]の[セグメント情報]をクリックでも可。
フォーマット/用語チェックに時間がかかりますが、良い方法はありますか?
フォーマットチェック/用語チェックは一括で行うことができます。
フォーマットチェック
- フォーマットチェックをかけたいランゲージペアをまとめて開きます。
- [レビュー] タブの [フォーマットチェック] グループにある [オプション] ボタンをクリックします。[フォーマットチェック] ウィンドウが開くので、チェックしたい項目を選択して [OK] を押します。
- [フォーマットチェック] グループの [開始] ボタンの下の▼から [ファイルナビゲーションウィンドウのエラー表示の更新] を選択します。ファイル全体にバックグラウンドでフォーマットチェックがかけられます。
用語チェック
- 用語チェックをかけたいランゲージペアをまとめて開きます。
- [用語] グループの [開始] ボタンの下の▼から [ファイルナビゲーションウィンドウのエラー表示の更新] を選択します。ファイル全体にバックグラウンドで用語チェックがかけられます。
フォーマットチェック/用語チェック結果の確認
- Transitウィンドウ左端の [ファイルナビゲーション] ウィンドウの左から2番目の [エラー(タイプ)] タブを開きます。
- 太字になっているものがエラーの検出された種類です。テキストの横にある+マークをクリックすると階層が開き、すべてのエラーリストを個別に表示できます。用語チェックの結果は「不正な用語」、フォーマットチェックの結果は選択したオプションに応じた項目の箇所に表示されます。
- エラーリストをダブルクリックすると、そのエラーが検出されたセグメントにカーソルが移動するので、必要に応じてエラーを修正します。
転送PPFに辞書や参照マテリアルを同梱する方法を教えてください。
- プロジェクト設定で、辞書や参照マテリアルを設定しておきます。
- リボンバー「プロジェクト」の「交換」から「転送」をクリックします。
「プロジェクトの転送」ダイアログが表示されるので「辞書のパック」にチェックマークを入れます。 - 「Transitオプション」をクリックします。
- 「プロジェクトのパックオプション」ダイアログが表示されるので「参照ファイル(E)」にチェックマークを入れ、「OK」をクリックし、ダイアログを閉じます。
- 「転送」をクリックすると辞書と参照マテリアルを同梱したPPFが作成されます。
TermStar辞書はどのような仕組みになっていますか?
TermStarでは、辞書はデータベースに作成されます。
データベースには、複数の辞書を格納できます。
イメージとしては、データベースが書棚、そこに収まる本が辞書に相当し ます。
辞書の作成方法を教えてください。
画面下リソースバーの [辞書] から、[辞書/データベース] - [新規辞書/データベースの作成] をクリックし、ウィザードに従って作成します。
新規辞書を作成する際には、以下の2つのオプションがあります。
- 辞書を既存のデータベースに追加
- 辞書を格納する新規データベースを作成
辞書には1つ1つ用語を登録することもできますが、Excelなどで蓄積したデータをインポートして使用することもできます。
弊社YouTube チャンネルの『Transit NXT : Quick Guide For Project Manager (Excel用語集をTransitで使用するには?)』では、ウィザードを使用したシンプルなExcelの用語データのインポート手順についてご紹介しています。どうぞご参照ください。
https://www.youtube.com/playlist?list=PLks6VFCyEeg3rgoO-CXCxP8Wwo18ejpcJ
TermStarのmdbの辞書をExcelでカンタンに一覧で見られるようにすることはできますか?
はい、TermStarのデータをExcel形式にエクスポートすることで、一覧で見られるようにすることができます。
逆に、Excel形式のデータをTermStarの辞書に取り込むこともできます。
詳しくは、下記の英語マニュアルを参照してください。
https://www.star-group.net/en/downloads/transit-termstar.html
Windows 11 に対応していますか?
2021年11月時点におきまして、当社ではWindows 11環境でTransit NXTが動作することを確認できておりません。
正常に動作することが確認でき次第、改めて当社Webサイト上でお知らせいたしますので、Transit NXTをお使いの皆様には、今しばらくの間、Windows 11のインストール、ならびにアップデートはお控えいただきますようお願いいたします。